



序
在B站看到C++课程于是尝试学习一下并记录以便巩固。
本文章大部分内容为学习课程的笔记,少部分为经过亲自实践/询问他人获得的额外经验。
记录跳转
第零部分:C++ 练习汇总
第一部分:C++学习记录 基础篇
第二部分:C++学习记录 核心篇
资源
【配套编程环境搭建】
https://www.bilibili.com/video/av44145245/?spm_id_from=333.788.b_765f64657363.1
【配套讲义】
基础篇:https://blog.csdn.net/ClaireSy/article/details/108422945
核心篇:https://blog.csdn.net/ClaireSy/article/details/108423047
提高篇:https://blog.csdn.net/ClaireSy/article/details/108423061
【课程学习】
https://www.bilibili.com/video/BV1et411b73Z
Hello World
1.基本的10行代码
#include<iostream>
using namespace std;
int main()
{
system("pause");
return 0;
}
2.Hello World的输出
cout<<"Hello World";
双引号中的字符串是可以任意修改的,写了什么就直接输出什么。
3.在2的基础上换行符endl的使用
cout<<"Hello World"<<endl;
注释
1.作用
在代码中加一些说明和解释,方便自己或其他程序员阅读代码。
2.语法
①.单行注释
//我是单行注释,编辑器不会处理我
即对该行代码说明。
通常放在一行代码上方,或者一条语句末尾。
②.多行注释
/*
我是
多行注释,
编辑器
也不会
处理
我
*/
即对该段代码做整体说明。
通常放在一段代码的上方。
【注:注释格式后/内字体颜色为绿色。】
3.暂且小提一下main函数
main是一个程序的入口,
每个程序都必须有这么一个函数,
有且仅有一个。
变量
1.作用
给一段指定的内存空间(C++中所有数据都会放到内存中)起名,方便操作管理这段内存空间。
2.语法
数据类型 变量名 = 初始值;
3.实践
①.尝试创建初始值为0的整型变量a并输出“a=0”
int a = 0;
cout<<"a="<<a;
常量
1.作用
用于记录程序中不可更改的数据(修改则改变原有意义,如一周有7天)。
2.语法
①.#define宏常量:
#define 常量名 常量值;
通常在文件上方(即main函数上方)定义,
表示一个常量。
②.const修饰的变量:
const 数据类型 常量名 = 常量值;
通常在变量定义前加关键词const,
修饰该变量为常量,不可修改。
【注:①中无赋值符号,②中有赋值符号。】
【注:常量分为字符串常量和const修饰的变量。】
3.实践
①.尝试用2中①和②分别创建常量7和12,并分行输出“一周有7天”“一年有12月”
#define Day 7;
const int Month = 12;
cout<<"一周有"<<Day<<"天"<<endl;
cout<<"一年有"<<Month<<"月";
标识符与关键字
1.定义
①.标识符是开发人员在程序中自定义的一些符号和名称,是自己定义的,如变量名 、函数名等。
②.关键字是C++中预先保留的标识符。
【注:关键字是特殊的标识符。】
【注:不允许开发者自己定义和关键字相同的名字的标识符(如变量、常量等),否则会产生歧义。】
2.标识符命名规则
①.标识符不能是关键字。
②.标识符只能由字母、数字、下划线组成。
③.标识符的首位字符必须是字母或下划线。
④.标识符中字母区分大小写。
【注:2019版本VS可用汉字命名标识符。】
【注:命名建议做到见名知义】
数据类型
1.作用
给变量分配合适的内存空间。
2.整型
作用
表示整数类型的数据。
类型
| 数据类型 | 占用空间 |
|---|---|
| short(短整型) | 2字节 |
| int(整型) | 4字节 |
| long(长整型) | Windows4字节,Linux4字节(32位)或8字节(64位) |
| long long(长长整型) | 8字节 |
注意
①.赋值若超出上限将输出下限,如短整型short的赋值范围为-32768~32767,如果
short x = 32768;
则输出的x值为-32768。
②.无特殊情况,最常用int。
③.整型大小比较:
short<int<=long<=long long
3.sizeof关键字
作用
统计数据类型所占内存大小。
语法
sizeof(数据类型或变量)
4.实型(浮点型)
作用
表示小数。
类别
| 数据类型 | 占用空间 | 有效数字范围 |
|---|---|---|
| float(单精度) | 4字节 | 7位有效数字 |
| double(双精度) | 8字节 | 15~16位有效数字 |
注意
①.默认情况下编译器会把小数识别为双精度,因此使用单精度变量时一般在赋值的小数末尾加f,如
float pi = 3.14f;
②.不管是单精度还是双精度,在输出小数时都会默认显示出6位有效数字,如需查看更多位数需要额外配置。
③.科学计数法:
1e2 表示 1乘10的平方
1e-2 表示 1乘0.1的平方
5.字符型
作用
表示单个字符。
语法
char 变量名 = '字符';
注意
①.显示字符型变量时,要用单引号将赋值的字符括起来,不是双引号。
②.①中单引号内只能由一个字符,不可以时字符串。
③.C和C++中字符型变量只占用1个字符。
④.字符型变量并不是把字符本身放到内存中存储,而是将对应的ASCII码值放入到存储单元。
⑤.查看字符型变量ch对应的ASCII码值的方法:
char ch = 'a';
cout << (int)ch;
这样输出的结果为:97。
⑥.关于ASCII编码:

ASCII表上的码值0~31分配给了控制字符(显如提示音、换行、回车等),用于控制像打印机等一些外围设备。
ASCII表上的码值32~126分配给了键盘上找到的字符,当查看或打印文档时就会出现。
顺便一提重点记住ASCII码值:48表示数字0,97表示字母a,65表示字母A,按顺序可以依次推导。
6.转义字符
作用
表示一些不能显示出来的ASCII字符。
类型

实践
①.尝试输出任意内容并使用转义字符“\n”换行?
cout<<"Shakuameji\n";
②.尝试输出“\”?
cout << "\\";
【注:第一个“\”是要告诉编译器咱要输出一个特殊的符号,因此两个反斜杠才能输出“\”】
③.尝试结合①输出三行,分别为“1喵”、“12喵”、“123喵”,并利用水平制表符(\t)使三行的喵左侧对齐。
cout << "1\t喵\n";
cout << "12\t喵\n";
cout << "123\t喵\n";
【注:灵活运用制表符可以起到整齐输出数据的作用。】
【注:其实水平制表符相当于:与该行“\t”前的字符一同占用8个字符的位置。因此即使每行“\t”左侧字符杂乱,右侧的字符也将左侧对齐。】
【注:若突然有一行的“\t”左侧的字符数已经大于7个,则会与多出前7位的字符重新一同占用8个字符的位置。当然此行“\t”右侧的字符将不会与上一行保持左侧对齐。】
7.字符串型
作用
表示一串字符。
语法
①.C语言字符串:
char 变量名[] = "字符串值";
②.C++字符串:
string 变量名 = "字符串值";
【注:两者相较字符型变量的语法都将赋值外的改为双引号。】
【注:C语言的字符串型变量语法额外需在变量名后加一个中括号。】
【注:使用C++字符串型变量时,需加入头文件 #include<string> 。】
【注:虽然输出时在双引号中书写内容也可以直接输出,但对于要重复输出的内容可以用字符串型变量。】
8.布尔(bool)类型
作用
代表真或假的类型。
注意
①.布尔数据类型变量的值只有ture、false和任意数字。
| ture | false | 非0数字 | 0 |
|---|---|---|---|
| 真 | 假 | 真 | 假 |
| 输出是1 | 输出是0 | 输出是1 | 输出是0 |
②.布尔数据类型所占1个字节大小,因为它本质上是1或0。
数据的输入
1.作用
从键盘获取数据
2.语法
cin >> 变量名;
【注:cin输入的值只取整型,即使你输入0.1,实际上输入的值只取到0。】
3.实践
①.尝试创建一个初始值为hello的字符串型变量str,让屏幕前的人给变量str重新赋值,重新输出变量str的值?
char str[] = "hello";
cout << "请为变量str重新赋值\n";
cin >> str;
cout << str << "\n";
【注:①中最后一行运用换行符时不可以直接加在变量名后,而是要加在双引号中。】
运算符
1.作用
执行代码的运算
2.类别
| 运算符类型 | 作用 |
|---|---|
| 算术运算符 | 处理四则运算 |
| 赋值运算符 | 将表达式的值赋给变量 |
| 比较运算符 | 表达式的比较,并返回一个真值或假值 |
| 逻辑运算符 | 根据表达式的值返回真值或假值 |
3.算术运算符
作用
处理四则运算
类别
| 运算符 | 术语 |
|---|---|
| + | 正号 |
| - | 负号 |
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| % | 取模(取余) | 10%3 | 1 |
| ++ | 前置递增 | a=2;b=++a; | a=3;b=3; |
| ++ | 后置递增 | a=2;b=a++; | a=3;b=2; |
| - - | 前置递减 | a=2;b=- -a; | a=1;b=1; |
| - - | 后置递减 | a=2;b=a- -; | a=1;b=2; |
注意
【除法运算符】
①.当创建的变量均为整型int时,两个整数做相除运算,结果也必须为整数。所以当运算结果有小数时将把小数部分舍去。注意是小数部分直接舍去,并非四舍五入。
②.当然,你也不允许把除数位置的数值设置为0。
③.当创建的变量均为实型(浮点型)float/double时,两个小数可以相除。并且结果可以为整数,也可以为小数。
【取模运算符】
④.其实就是运用于无法整除的情况求余数。
⑤.该运算符只运用在除法运算中,因此该运算符后面的位置即除数的位置也不能是0。
⑥.该运算符前后都不允许是小数。只有整型变量可以进行取模运算。
【递增/递减运算符】
⑦.顾名思义,递增/递减就是+1/-1。
⑧.前置递增与后置递增的区别:
前置递增先让变量+1,然后进行赋值或其他表达式运算。
后置递增先进行赋值或表达式的运算,然后变量+1。
前置递减与后置递减的区别原理相同。
3.赋值运算符
作用
将表达式的值赋给变量。
类别
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| = | 赋值 | a=2;b=3; | a=2;b=3; |
| += | 加等于 | a=0; a+=2; | a=2; |
| -= | 减等于 | a=5; a-=3; | a=2; |
| *= | 乘等于 | a=2; a*=2; | a=4; |
| /= | 除等于 | a=4; a/=2; | a=2; |
| %= | 模等于 | a=3; a%2; | a=1; |
注意
①.举个便于理解の栗子:a+=2相当于a(现在)=a(原来)+2,相当于对a重新赋值。
4.比较运算符
作用
表达式的比较,并返回一个真值或假值。
类别
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| == | 相等于 | 3==4 | 0 |
| != | 不等于 | 3!=4 | 1 |
| < | 小于 | 4<3 | 0 |
| > | 大于 | 4>3 | 1 |
| <= | 小于等于 | 4<=3 | 0 |
| >= | 大于等于 | 4>=3 | 1 |
注意
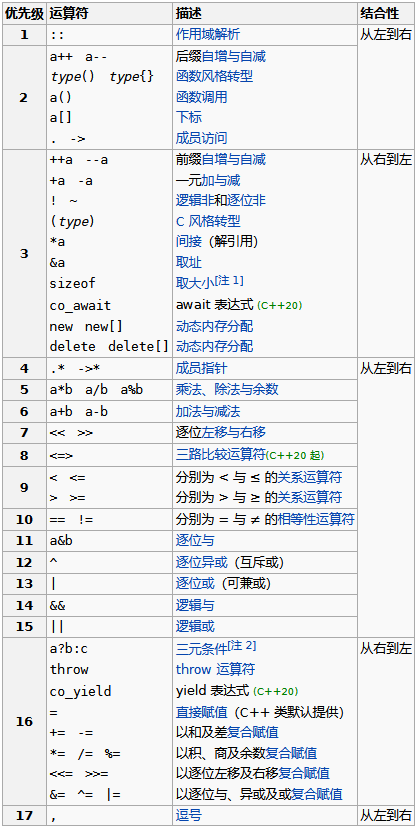
①.优先级:对想要先执行的运算符包含的表达式两端加上小括号。最常见的如cout << ( a == b ) << endl;,换行符前的<<优先级高于==,因此需要在比较运算式两端加括号。
②.优先级顺序表:
5.逻辑运算符
作用
根据表达式的值返回真值或假值。
类别
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| ! | 非 | !a | 如果a为真,则!a为假;如果a为假,则!a为真 |
| && | 与 | a&&b | 仅当a和b都为真时,结果为真,其余都为假 |
| || | 或 | a||b | 仅当a和b都为假时,结果为假;其余都为真 |
注意
①.口诀:
非——“真变假,假变真”
与——“同真为真,其余为假”
或——“同假为假,其余为真”
②.在c++中赋的值除了0,都为真。
例如:
int a = 10 ;
cout << !a << endl;
cout << !!a << endl;
逻辑运算符用于根据表达式的值返回真值或假值。因此第一次输出结果为0,第二次输出结果为1。
程序流程结构
1.类别
| 结构 | 作用 |
|---|---|
| 顺序结构 | 程序按顺序执行,不发生跳转 |
| 选择结构 | 依据条件是否满足,有选择的执行相应功能 |
| 循环结构 | 依据条件是否满足,循环多次执行某段代码 |
2.选择结构
if语句
作用
执行满足条件语句。
语法
①.单行格式if语句:
if (条件)
{
条件满足执行的语句
}
②.多行格式if语句:
if (条件)
{
条件满足执行的语句
}
else
{
条件不满足执行的语句
}
③.多条件的if语句:
if (条件1)
{
条件1满足执行的语句
}
else if (条件2)
{
条件2满足执行的语句
}
...
else
{
所有条件均不满足执行的语句
}
注意
①.if条件语句末尾不加分号。
②.嵌套if语句
if (条件1)
{
if (条件2)
{
条件1满足下且符合条件2执行的语句
}
}
三目运算符
作用
实现简单的判断。
语法
表达式1 ? 表达式2 : 表达式3
如果表达式1为真,执行表达式2,并返回表达式2的结果。
如果表达式1为假,执行表达式3,并返回表达式3的结果。
实践
①.尝试创建a、b和c三个变量,并运用三目运算符将b与c变量中较大的值赋给a?
int a = 0;
int b = 1;
int c = 2;
a = b>c?b:c;
因为b>c为假,所以执行给a赋c的值。
②.尝试结合①给由三目运算符返回的变量重新赋值为3?
(b>c?b:c) = 3;
【注意:C++中三目运算符返回的是变量,可以继续赋值。】
switch语句
作用
执行多条件分支语句。
语法
switch (表达式)
{
case 结果1:
表达式结果为结果1时执行语句
(break;)
case 结果2:
表达式结果为结果2时执行语句
(break;)
...
default:
表达式结果没有满足的时执行的语句
(break;)
}
注意
①.当遇到break语句时,switch终止,控制流将跳转到switch语句后的下一行。
case下的break:不是每一个 case都需要包含break。如果case语句不包含break,控制流将会继续后续的case和里面的输出且无视case后的赋值条件,直到遇到break为止(如果default下面依然没有break将意味着输出了整个switch里的所有语句)。所以当只想根据case条件选择一个输出时,要在每个case下加break。
default下的break:当default放在所有case下(即绝大多数的情况),可以不加break。但如果default下仍有case,则需要考虑是否加break跳出switch还是不加break执行下面case里的语句。
② .if和switch的区别?
执行效率:switch > if
【注:switch结构更清晰。】
适用性:if > switch
【注:switch判断的时候表达式必须是一个整型或枚举类型,或者是一个 class类型,如int、short、char、byte,enum。但string,Long、double、float都不能作用于swtich。且switch的判断值不可以是一个区间。但if判断时表达式可以为一个区间。】
3.循环结构
while语句
作用
满足循环条件,执行循环语句。
语法
while(循环条件)
{
循环语句
}
实践
①.尝试运用while循环语句在屏幕上输出0~9这10个数字?
int num = 0;
while (num <= 9)
{
cout << num << endl;
num++;
}
②.【案例:猜数字】系统生成随机数(1~100),玩家进行猜测,猜对则退出,猜错则提示过大或过小。
srand((unsigned int)time(NULL));
int num = rand()% 100 +1;
int guess = 0;
while (1)
{
cout <<"请输入您猜测的数字?"<< endl;
cin >> guess;
if (guess > num)
{
cout << "要比您猜的数字小呢。"<< endl;
}
else if (guess < num)
{
cout << "要比您猜的数字大呢。"<< endl;
}
else
{
cout <<"恭喜猜对了欸!"<< endl;
break;
}
}
注意
①.当while语句中循环条件填写非0的数字时,相当于“真”(即没有条件),将持续不断地执行其内部的循环语句(即出现死循环)。
②.C++中生成伪随机数的函数rand来表示0~上限-1,其语法如下:
rand()% 上限;
③.如何打破伪随机数?可以在创建的随机数对应的变量前添加随机数种子,利用系统时间生成随机数。
其语法如下:
srand((unsigned int)time(NULL));
当然,你需要先添加time系统时间头文件#include< ctime >。
④.在循环中可以运用关键字break来退出循环。
do…while语句
作用
先执行一次循环语句,其后若满足循环条件,执行循环语句。
语法
do
{
循环语句
}
while (循环条件);
注意
①.do…while语句中while()后有分号。
实践
①.【案例:水仙花数】输出所有三位的水仙花数。
int num = 100;
do
{
int ge = num % 10;
int shi = num / 10 % 10;
int bai = num / 100;
if (ge*ge*ge + shi*shi*shi +
bai*bai*bai== num )
{
cout << num << endl;
}
num++;
}
while (num <= 999);
注意
①.取三位数的个位、十位和百位…的方法:
个位——取模于10;
十位——除于10再取模于10;
百位——除于100;
②.【错误补正】在实践①中:
第一次尝试的时候把个十百位的变量放到了do…while语句的前面,这样这三个变量的赋值只进行1次,而不是依次取递增的num的个十百位。
for语句
作用
满足循环条件,执行循环语句。
语法
for (起始表达式;条件表达式;末尾循环体)
{
循环语句
}
实践
①.【案例:敲桌子】依次输出1-100且把其中个位或者十位是7或者是7的倍数的数字替换为敲桌子。
for (int num =1;num<101;num++)
{
if (num%10 == 7 || num/10 == 7 || num%7 == 0)
{
cout << "敲桌子" << endl;
}
else
{
cout << num << endl;
}
注意
①.for语句后括号内的三个表达式都可以拆分成单行。实际上执行的循环顺序为:起始表达式(只执行1次)→条件表达式(即循环条件)→循环语句→末尾循环体。
②.for语句的结构比较清晰。
③.【优解补正】在实践①中:
判断循环条件时我用了好多else if,答案把各个循环条件运用逻辑运算符“||”放在一个if里。
且我创建了三个变量,其实可以直接书写在循环条件表达式里。
嵌套循环
作用
在循环体中再嵌套一层循环。
实践
①.尝试输出一份10x10的星(由*构成)图?
for (int i = 0;i < 10;i++)
{
for (int j = 0;j < 10;j++)
{
cout << "* ";
}
cout << endl;
}
②.【案例:九九乘法表】利用嵌套循环,实现九九乘法表。
for (int i = 1;i < 10;i++)
{
for (int j = 1;j <= i;j++)
{
cout << j << "x" << i << "=" << j*i << " ";
}
cout << endl;
}
注意
①.嵌套循环的原理:外层执行一次,内层执行一周。
②.【错误补正】在实践①中for循环语句括号里第一个起始表达式一定要书写数据类型。
③.就近原则:
如果在嵌套循环外层与内层两个变量名一样,那么输出的变量的值取就近的该变量的值。
④.【错误补正】在实践②中:
此处内外两层起始表达式可以拆分到各自的循环体上方,但不可都放于外层循环体上面创建,否则内层循环体执行一周后,其变量j在外层第二次循环时不会重新从初始值计算,而是外层第一次循环结束时的值(即i的值)。这样得到的乘法表只是两个相同的数相乘的所有程式。
换行应写在外层循环体,若写在内层循环体则将每输出一个程式便换一行,最终结果一个程式一行。实际想要的是效果是内层循环体执行一周后再换行。
4.跳转语句
break语句
作用
跳出选择结构或者循环结构。
类别
| 使用时机 | 作用 |
|---|---|
| switch条件语句 | 终止case并跳出switch |
| 循环语句 | 跳出当前循环语句 |
| 嵌套循环 | 跳出最近的内层循环语句 |
语法
①.switch条件语句情况下:
swith (表达式)
{
case 结果1:
表达式结果为结果1时执行语句
break;
case 结果2:
表达式结果为结果2时执行语句
break;
...
default:
表达式结果没有满足的时执行的语句
break;
}
②.循环语句情况下:
for (起始表达式;条件表达式;末尾循环体)
{
if (条件)
{
break;
}
循环语句
}
②.嵌套循环语句情况下:
for (起始表达式1;条件表达式1;末尾循环体1)
{
for (起始表达式2;条件表达式2;末尾循环体2)
{
if (条件)
{
break;
}
循环语句1
}
循环语句2
}
continue语句
作用
在循环语句中, 跳过本次循环中余下尚未执行的语句,继续执行下一次循环。
实践
①.尝试运用循环语句和continue语句输出0~100中的所有奇数?
for (int i = 0;i <= 100;i++)
{
if (i%2 == 0)
{
continue;
}
cout << i << endl;
}
注意
①.break语句与continue语句的区别:
continue并不会直接使循环终止,而是不执行循环体内位于其下方的语句,可以搭配if语句使用;但break语句会直接跳出循环体,终止循环。
goto语句
作用
无条件跳转代码。
语法
goto 标记;
实践
①.尝试运用goto语句随意书写几行代码输出些东西?
cout<< "些" ;
cout<< "东" ;
goto SHAKUAMEJI;
cout<< "喵喵喵" << endl;
SHAKUAMEJI:
cout<< "西" << endl;
注意
①.标记一般写成纯大写的单词,命名规则和标识符命名规则相符。
②.如果标记在goto语句的上方相当于循环且很可能是死循环。
数组
1.作用
作为一个集合,在里面存放了相同类型的数据元素
2.类别
①.一维数组
②.二维数组
3.一维数组
语法
①.
数据类型 数组名[ 数组长度 ];
②.
数据类型 数组名[ 数组长度 ] = { 值1,值2... };
③.
数据类型 数组名[] = { 值1,值2... };
实践
①.尝试声明一个5个元素的数组并从中输出最大值?
int arr[5] = {1,3,4,2,5};
int max = 0;
for(int i = 0 ;i<5;i++)
{
if ( arr[i] > max )
{
max = arr[i];
}
}
cout << max;
②.【案例:元素逆置】声明一个5个元素的数组并使元素排列顺序倒置并输出,但不允许直接引用具体下标进行替换。
int arr[5] = {1,2,3,4,5};
int start = 0;
int end = sizeof(arr)/sizeof(arr[0]) - 1;
while (start < end)
{
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
start++;
end--;
}
cout << "元素逆置后arr[5] = {";
for(int i = 0;i<sizeof(arr)/sizeof(arr[0]);i++)
{
cout << arr[i] ;
if (i < end+2)
{
cout << ",";
}
}
cout << "}";
cout << endl;
注意
①.数组中的每个数据元素都是相同的数据类型。
②.数组是由连续的内存位置组成的。
③.下标:

④.数组内元素下标从0开始索引。
⑤.若初始化数组内数据时填写的值数少于数组长度,则会用0来填补剩余值数的数据。
⑥.数组名的命名与变量命名规则一致,且不能和变量名重复。但数组名是一个常量,不能对数组名重新赋值。
⑦.一维数组数组名用途:
1)统计整个数组或莫个下标对应的元素在内存中的长度:
sizeof (数组名或数组名[下标])
2)统计数组中元素个数:
sizeof(数组名)/sizeof(数组名[0])
【注:因此求数组中末尾元素下标为: sizeof(数组名)/sizeof(数组名[0]) - 1 。】
3)获取数组在内存中的首地址:
十六进制:
cout << 数组名;
十进制:
cout << (int)数组名;
【注:数组的首地址即第一个元素的地址。】
4)获取数组中某个下标对应的元素在内存中的首地址:
十六进制:
cout << &数组名[下标];
十进制:
cout << (int)&数组名[下标];
冒泡排序
作用
最常用的排序算法,对数组内的元素进行排序。
实践
①.尝试将数组arr{4,2,8,0,5,7,1,3,9}进行升序排序并输出?
int arr[9]={4,2,8,0,5,7,1,3,9};
for (int i = 1;i <= 9;i++)
{
for (int j = 1;j <= 9-i ;j++)
{
if (arr[j-1] > arr[j])
{
int temp = arr[j-1];
arr[j-1] = arr[j];
arr[j] = temp;
}
}
}
cout << "升序排序后arr[9] = {";
for(int a = 0;a<sizeof(arr)/sizeof(arr[0]);a++)
{
cout << arr[a];
if (a < sizeof(arr)/sizeof(arr[0])-1)
{
cout << ",";
}
}
cout << "}";
cout << endl;
注意
①.逻辑:
1)先将所有数分为两两相邻的一组,共(数目-1)组,从前至后依次比较每一组相邻的两个数,若第一个比第二个大,则交换他们两个,进行(数目-1)次比较,此为第一轮。
2)第一轮最后一组两数交换后,只能确保最末尾的数必定为所有数中最大数,且前面的数未必是按序排列,因为每组都是单独、依次比较的。
3)重复以上步骤,每轮比较次数为数目减去抛去过往几轮中已确定的几个末位数后(因为每轮末尾数都是最大数,它便不用参与下一轮排序)再减1,相当于数目-当前轮数,直至不需要比较。
②.规律:
1)排序总轮数 = 数目
2)每轮对比次数 = 数目 - 当前轮数
【注:规律里的排序轮数和对比次数都从1开始记】
【注:因为对比时要通过数组下标从0开始找元素,所以在写for嵌套内层循环实现每组的比较时调用的下标都要-1,即比较j-1和j的大小】
【注:冒泡排序中我感觉循环条件都使用<=好,方便理解代码含义。】
③.实践①中的“替换逻辑”要熟记:
先把前者存入temp,再把前者赋值成后者,最后把后者赋值成temp。
4.二维数组
语法
①.
数据类型 数组名[行数][列数];
数组名[行][列] = 值1;
数组名[行][列] = 值2;
数组名[行][列] = 值3;
数组名[行][列] = 值4;
...
【一维数组从0开始下标,二维同理,所以2行2列的数组分别是:(0,0)(0,1)(1,0)(1,1)】
【输出二维数组内某一元素也要注意下标从0开始】
②.
数据类型 数组名[行数][列数] =
{
{值1,值2... },
{值3,值4... },
};
③.
数据类型 数组名[行数][列数] = {值1,值2,值3,值4... };
④.
数据类型 数组名[][列数] = {值1,值2,值3,值4... };
实践
①.【案例:成绩之和统计】A、B和C一同参加3场考试,假设A取得100,100,100;B取得70,80,90;C取得40,50,60。请分行输出三人的成绩之和。
char names[3] = {'A','B','C'};
int scores[3][3] =
{
{100,100,100},
{70,80,90},
{40,50,60},
};
for (int i = 0;i<3;i++)
{
int sum = 0;
for (int j = 0;j<3;j++)
{
sum += scores[i][j];
}
cout << names[i] << "的总成绩为:" << sum << "分。\n";
}
注意
①.一般采用语法中第②种创建数组,因为其更直观且可读性强。
②.可以利用嵌套循环输出二维数组(矩阵)内所有元素:外层循环创建行的下标变量,外层循环创建行的下标变量。打印矩阵效果则可以在内层循环体下方加入输出换行。
③.二维数组数组名用途:
1)统计整个数组或第n行或第x行第y列对应的元素在内存中的长度:
sizeof (数组名或数组名[n-1]或数组名[x-1][y-1])
【注:因此二维数组行数为:sizeof(数组名)/sizeof(数组名[0])。】
【注:因此二维数组列数为:sizeof(数组名[0])/sizeof(数组名[0][0])。】
2)获取二维数组首地址或其第n行首地址:
十六进制:
cout << 数组名或数组名[n-1] ;
十进制:
cout << (int)数组名或(int)数组名[n-1] ;
【注:实际上二维数组首地址,第一行首地址,第一个元素首地址相同。】
2)获取二维数组第x行第y列元素首地址:
十六进制:
cout << &数组名[x-1][y-1];
十进制:
cout << (int)&数组名[x-1][y-1];
④.【忘却补正】在实践①中:
书写二维数组语法频繁出错,应注意:每行的开头结尾都有大括号;除最后一行外的前面所有行末尾都有逗号;最后一个回大括号后面还有一个分号。
书写创建char语法时出错,应注意:要用单引号将赋值的每一个字符括起来。
尾句书写转义字符换行时出错,应注意:换行的转义字符是反斜线+n,反斜线是\(“向右为反”!!!正斜线一般用于目录!!!)。
函数
作用
将一段经常使用的代码封装起来,减少重复代码。
语法
返回值类型 函数名(形参列表)
{
函数体语句
return 表达式
}
注意
①.一个较大的程序,一般分为若干程序块,每个模块实现特定的功能。
②.参数列表是什么意思呢?
即对使用函数时输入的数据。比如我要输入一个整数,则参数列表为:int num1 。
③.返回值类型和return表达式的关系?
返回值类型与return表达式返回的数据类型应相同。
函数的调用
作用
使用定义好的函数
语法
函数名 (参数);
实践
①.尝试定义一个整数加法函数并在main函数中调用并输出?
int add (int num1,int num2)
{
int sum;
sum = num1 + num2;
return sum;
}
int main()
{
int a;
int b;
cout <<"请输入第一个整数?"<<endl
cin >> a;
cout <<"请输入第二个整数?"<<endl
cin >> b;
int sum = add(a,b);
cout << "它们相加之和为:" << sum <<endl;
system("pause");
return 0;
}
注意
①.实践①中num1、num2叫形式参数(形参),a、b叫实际参数(实参)。当调用函数时,实参的值会传递给形参。
②.【忘却补正】在实践①中:
书写add函数体语句时,忘记为sum创建变量。
书写mian函数体语句时,多次忘记为文本输出两端加双引号。
忘记书写mian函数return表达式。
值传递
作用
在调用函数时,将实参数值传递给形参。且在值传递时,形参发生改变并不会影响实参。
实践
①.尝试定义一个可以实现交换输入的两个变量数值的函数,并输出交换后的结果?
void swap(int num1,int num2)
{
int temp = num1;
num1 = num2;
num2 = temp;
cout<<"交换后num1的值为:"<< num1 <<endl;
cout<<"交换后num2的值为:"<< num2 <<endl;
}
int main()
{
int a;
int b;
cout<<"请为整型变量num1赋值?"<<endl;
cin>>a;
cout<<"请为整型变量num2赋值?"<<endl;
cin>>b;
swap(a,b);
system("pause");
return 0;
}
注意
①.如果定义函数时不需要返回值,则可以声明返回值类型为void,并且return表达式也不需要写或者只写为return;。
②.【错误补正】在实践①中:
当前在做值传递,即使形参num1,num2交换改变,但实参a,b不受影响,因此若想通过调用swap输出交换,则应该在swap函数体里书写输出语句。
且需要注意swap函数和main函数里创建的变量并不通用,swap函数体中只能出现参数列表里或在函数体语句内创建的变量名。
③.为什么上一组实践即加法函数中没有值传递时形参不影响实参的问题?
因为上一组实践①中:main函数输出语句引用的是sum,sum是add函数中额外创建的变量,它既不是形参也不是实参。
函数常见样式
语法
①.无参无返
void 函数名()
{
函数体语句
}
②.无参有返
返回值类型 函数名()
{
函数体语句
return表达式
}
③.有参无返
void 函数名(形参列表)
{
函数体语句
}
④.有参有返
返回值类型 函数名(形参列表)
{
函数体语句
return表达式
}
函数的声明
作用
当函数定义于main函数后方且于main函数中被调用时,编译器编译至调用函数时不清楚该函数的存在,将报错找不到该标识符。为此,需要先对函数进行声明处于main函数后方的函数。
语法
返回值类型 函数名(形参列表);
注意
①.函数可以声明多次,但只能定义一次。但一般情况也不会多次声明。
函数的分文件编写
作用
使代码结构更加清晰。
步骤
①.创建 函数名.h 的头文件。
②.创建 函数名.cpp 的源文件。
③.在头文件中包含基本框架并声明函数
④.在源文件中包含头文件并定义函数
【注:步骤③中的基本框架被包含在头文件或其对应的源文件都行,个人感觉 把基础框架和头文件都包含到源文件,头文件中只有函数的声明 比较整齐…】
注意
①.头文件.h 或 头文件对应的源文件.cpp 要包含如下基本框架:
#include<iostream>
using namespace std;
②.在头文件对应的源文件.cpp 和 总源文件.cpp 中都要包含头文件的语法,如下:
#include "函数名.h"
【注:函数名两端不再是<>而是"",意味这个头文件是我们编写的。】
③.调用方法: 函数分文件后,任意需要调用函数的源文件都需要包含其函数头文件,语法同注意②。
指针
作用
可以通过指针间接访问内存。
语法
①.定义指针并让指针记录变量的地址:
指针类型 指针名 = &变量名;
【指针类型:数据类型* ,如:int*】
②.解引用
*指针名
【注:指针数据类型要和对应的变量的数据类型一致。】
注意
①.内存编号从0开始记录,一般用十六进制数字表示。
②.可以利用指针变量保存地址,即指针就是地址。
③.可以通过解引用的方式来找到指针指向的内存中的数据,即间接访问,即变量 = *变量对应的指针。
④.可以通过解引用间接修改内存数据,类似对变量重新赋值,如*指针名 = 重新赋值。
指针所占的内存空间
语法
sizeof(指针类型)
注意
①.任意数据类型指针在同一操作系统下占用内存空间相同,表格如下:
| 操作系统 | 内存空间 |
|---|---|
| 32位(x86) | 4字节 |
| 64位(x64) | 8字节 |
空指针和野指针
定义
①.空指针:指针变量指向内存中编号为0的空间,用于初始化指针变量。
②.野指针:指针变量指向非法的内存空间。
语法
①.空指针:
指针类型 指针名 = NULL;
②.野指针:
指针类型 指针名 = (指针类型)内存地址;
注意
①.空指针指向的内存不可以访问,因为0-255内存编号为系统占用内存,不允许用户访问。
②.在程序中避免出现野指针,因为指向的地址不属于当前进程地址空间(不是我们申请的内存空间),属于越界异常,也不可以访问。
③.野指针成因:指针仅仅定义没有被初始化或后期被释放、删除从而使人误以为还是合法指针。
const修饰指针
类别&定义&作用
| 类别 | 定义 | 作用 |
|---|---|---|
| 常量指针 | const限制指针类型,本质指针 | 地址可改(值可因此而改变),不可通过解引用改值 |
| 指针常量 | const限制指针(即地址),本质为常量 | 可解引用直接重赋值(改地址的值),但地址固定 |
| 常量指针常量 | const修饰指针和常量 | 和值皆固定 |
常量指针中:const仅限制指针类型,指针可变,解引用(* 指针)相当于改变指针类型为数据类型(int*[8字节] → int[4字节]),所以不能通过解引用重赋值,但可改变指针(地址)进而改变值;指针常量中const仅限制指针,指针即地址,因此地址不能改,但地址对应的数据可以通过解引用改
语法
①.常量指针
const 指针类型 指针名 = &变量名
②.指针常量
指针类型 const 指针名 = &变量名
①.常量指针常量
const 指针类型 const 指针名 = &变量名
注意
①.硬记版:const在* 左侧不能直接改值,在* 右侧不能改地址
②.不管是哪种类型,尽管名字带常量,但其对应的不一定是常量还是变量,但如果是常量,则不能使用指针常量。
麻了,西风提到的:const RawPtr < int >,咱也不会啊,以后再说8。
指针和数组
作用
利用指针访问数组中的元素。
语法
①.初始化指针为数组地址:
指针类型 指针名 = 数组名;
②.利用指针访问数组中下一个元素:
指针名++;
实践
①.尝试利用指针打印一个数组中的全部元素(即遍历数组)?
int arr[] = { 1,2,3,4,5 };
int* p = arr;
for (int a = 0;a < sizeof(arr)/sizeof(arr[0]);a++)
{
cout << "数组中第" << a + 1 << "个元素是:" << *p << endl;
p++;
}
}
注意
①.语法①中不需要取址符号&,因为数组名就是数组的首地址,即第一个元素的地址。
②.可以通过语法②依次访问数组中下一个的元素,例如实践①。
指针和函数(地址传递)
作用
利用指针作函数参数,可以修改实参的值,即地址传递。
语法
数据类型 函数名(指针类型 形参名 ... )
{
函数体语句
return 表达式
}
函数名(&实参名);
注意
①.值传递和地址传递的区别:
1)值传递中形参不会影响实参。因为形参得到的是调用该函数时实参中拷贝的数值。该调用的函数中改变形参数值后,全局中实参地址上的数据没有改变。
2)地址传递中形参会影响实参。因为形参得到的是调用该函数中实参拷贝的地址,通过解引用地址可以得到、改变数据,但这时候改变数据是通过解引用改变的形参地址上的数据。这时候原来函数中实参对应的数据自然也被更改了,因为形参实参地址是同一个。
总而言之,内存中可以有一样的变量名(即不同函数中),但任何函数中都不能有一样的地址。更改不同地址上相同变量名的数值可以是局部的,但更改地址上的数值一定是全局的。
②.调用函数时实参若为数组则不需要取址符号。
const与地址传递的相辅相成
作用
通过使用const禁用地址传递修改实参的功能,防止误操作。
语法
数据类型 函数名(const 指针类型 形参名)
{
函数体语句
return 表达式
}
函数名(&实参名)
注意
①.多用地址传递少用值传递,因为值传递复制实参值传递到形参消耗内存较多,同时使用const即可禁用地址传递修改实参的功能。
指针&数组&函数综合案例
实践
①.尝试封装一个利用冒泡排序的函数,实现对整型数组{4,3,6,9,1,2,10,8,7,5}的升序排序?
void sort(int* p,int len)
{
for (int i = 1 ; i <= len ; i++)
{
for (int j = 1 ; j <= len-i ; j++)
{
if (*(p+ (j-1) ) > *(p+ (j) ) )
{
int temp = *(p+ j );
*(p+ j ) = *(p+ j-1 );
*(p+ j-1 ) = temp;
}
}
}
}
int main()
{
int arr[] = {4,3,6,9,1,2,10,8,7,5};
int len = sizeof(arr) / sizeof(arr[0]);
sort(arr,len);
cout << "升序排序后arr[" << sizeof(arr)/sizeof(arr[0]) << "] = {";
for(int a = 0;a<sizeof(arr)/sizeof(arr[0]);a++)
{
cout << arr[a];
if (a < sizeof(arr)/sizeof(arr[0])-1)
{
cout << ",";
}
}
cout << "}";
cout << endl;
}
注意
①.参数[变量]=*(参数+变量), 比如实践①中* (p+j)也可以写为p[j]。
②.【错误补正】在实践①中:
封装sort函数时若不返回数据则函数数据类型要写成void。
要在main函数中计算数组长度然后作为实参传入形参。
存疑,试图不用len,直接在sort函数里计算数组长度,失败了。
调用sort函数时实参len前不需要加取址符号,因为在形参里也没有用指针指向len的地址,针对len而言sort只是普通的函数而与地址传递无关。
结构体
定义
与编译器内定的数据类型(如:int,bool,char等)不同,结构体是用户自定义的数据类型,允许用户存储不同的数据类型(即一些数据类型集合组成的一个类型)。
语法
①.创建结构体数据类型(定义结构体):
struct 结构体数据类型名
{
数据类型1 变量名1;
数据类型2 变量名2;
...(成员列表)...
};
【注:定义结构体最后一个大括号后面有;】
②.创建结构体变量:
方法1: 已创建结构体数据类型后创建结构体变量
struct 结构体数据类型名 结构体变量名;
方法2: 创建结构体数据类型同时创建结构体变量
struct 结构体数据类型名
{
数据类型1 变量名1;
数据类型2 变量名2;
...(成员列表)...
}结构体变量名;
③.为结构体变量赋值
方法1: 已创建结构体变量后赋值
结构体变量名.成员列表变量名 = 值;
方法2: 已创建结构体数据类型后创建结构体变量同时赋值
struct 结构体数据类型名 结构体变量名 = { 值1,值2 ... }
【注:方法2赋值要按成员列表顺序依次赋值。】
实践
①.尝试创建一个名为student的数据类型并对其创建name,score,age的成员列表?然后创建变量student1并对成员列表分别赋值为雨心,100,19?
struct student
{
string name;
float score;
int age;
};
struct student student1;
student1.name = "雨心";
student1.score = 100;
student1.age = 19;
注意
①.赋值为汉字等字符串需要引用字符串头文件#include <string>。
②.赋值字符串型变量时,要用双引号将赋值括起来。
③.已创建结构体数据类型后创建结构体变量时可以不写struct。
④.【忘却补正】实践①创建结构体数据类型最后一个大括号后一定要写; 。
结构体数组
作用
定义结构体后,将自定义的结构体变量放入到结构体数组中方便维护。
语法
①.创建结构体数组
方法1:
struct 结构体数据类型名 结构体数组名[元素个数];
方法2:
struct 结构体数据类型名 结构体数组名[] = { { },{ },... };
②.对结构体数组内结构体变量赋值
方法1: 已创建结构体数组后赋值
结构体数组名[下标].成员列表变量名 = 值;
方法2: 创建结构体数组同时赋值
struct 结构体数据类型名 结构体数组名[元素个数] =
{
{ 值1,值2 },
{ 值1,值2 },
... ...
};
【注:语法和二维数组相似,每个结构体变量赋值大括号后都有, 】
结构体指针
作用
通过指针访问结构体变量中的成员列表变量数据。
语法
①.定义指针并让指针记录变量的地址:
指针类型 指针名 = &结构体变量名;
【注:指针类型即结构体数据类型名*】
②.通过指针访问结构体变量中的成员列表变量:
指针名->成员列表变量名
嵌套结构体
作用
母结构体数据类型中成员列表的一个数据类型是子结构体数据类型。
语法
①.定义嵌套结构体:
struct 子结构体数据类型 {成员列表1};
struct 母结构体数据类型
{
子结构体数据类型 子结构体变量名;
...... (成员列表2) ...
};
【注:先定义子结构体,再定义母结构体】
②.创建母结构体变量并赋值:
方法1: 创建变量后赋值:
母结构体数据类型 母结构体变量名;
母结构体变量名.子结构体变量名.子结构体成员列表变量名 = 值 ;
方法2: 创建变量同时赋值:
母结构体数据类型 母结构体变量名 = {母结构体值 ... , 子结构体值 ... };
【注:方法2赋值要按母/子结构体成员列表顺序依次赋值。】
实践
①.尝试创建嵌套结构体表示1对1补习班老师与学生的信息关系并用语法②中的方法2为teacher1赋值?
struct student
{
string name;
int age;
float score;
};
struct teacher
{
int id;
string name;
int age;
struct student stu;
};
int main()
{
teacher teacher1 = {001,"老师",30,"雨心",19,100}
}
注意
①.【忘却补正】实践①中定义结构体末尾大括号后一定要有;
②.实践①中为teacher1赋值前三个值是母结构体变量teacher1的,后三个变量为子结构体变量stu的。
结构体做函数参数
作用
将结构体作为参数向函数中传递
语法
①.值传递:
数据类型 函数名(结构体数据类型 形参名 ... )
{
函数体语句
return 表达式
}
函数名(结构体变量名)
②.地址传递:
数据类型 函数名(指针类型 形参名 ... )
{
函数体语句
return 表达式
}
函数名(&结构体变量名)
注意
①.值传递改变形参后实参不变。
https://blog.shakuameji.com/archives/cstudy1#值传递
②.地址传递改变形参后实参改变。
https://blog.shakuameji.com/archives/cstudy1#指针和函数(地址传递)
③.多用地址传递少用值传递,因为值传递复制实参值传递到形参消耗内存较多,地址传递只占用4字节;同时使用const即可禁用地址传递修改实参的功能。
https://blog.shakuameji.com/archives/cstudy1#const与地址传递的相辅相成
实践
①.

struct Student
{
string sName;
int score;
};
struct Teacher
{
string tName;
struct Student sArray[5];
};
void allocate (Teacher tArray[] , int len , string nameseed)
{
for (int i=0 ; i<len ; i++)
{
tArray[i].tName = "Teacher_";
tArray[i].tName += nameseed[i];
for(int j=0 ; j<5 ; j++)
{
tArray[i].sArray[j].sName = "Student_";
tArray[i].sArray[j].sName += nameseed[j];
int random = rand()%61+40;
tArray[i].sArray[j].score = random;
}
}
}
void printinfo (Teacher tArray , int len)
{
for(int i=0 ; i<len ; i++)
{
cout << tArray[i].tName << endl;
for(int j=0 ; j<5 ; j++)
{
cout << "\t学生姓名:" << tArray[i].sArray[j].sName <<
"成绩:" << tArray[i].sArray[j].score << endl;
}
}
}
struct Teacher tArray[3];
int len = sizeof(tArray)/sizeof(tArray[0]);
string nameseed = "ABCDE";
srand((unsigned int)time(NULL));
allocate(tArray , len , nameseed);
printinfo(tArray , len);
②.
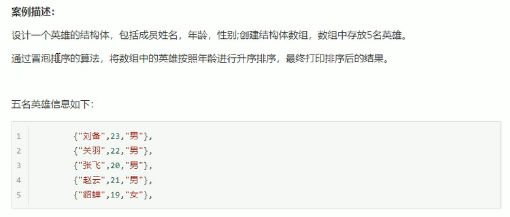
struct hero
{
string name;
int age;
string sex;
};
void bubbleSort(hero heroArray[] , int len)
{
for(int i = 1;i<=len;i++)
{
for(int j =1;j<=len-i;j++)
{
if(heroArray[j-1].age > heroArray[j].age)
{
hero temp = heroArray[j-1];
heroArray[j-1] = heroArray[j];
heroArray[j] = temp;
}
}
}
}
hero heroArray[5]=
{
{"刘备",23,"男"},
{"关羽",22,"男"},
{"张飞",20,"男"},
{"赵云",21,"男"},
{"貂蝉",19,"女"},
};
int len = sizeof(heroArray)/sizeof(heroArray[0]);
bubbleSort(heroArray , len);
cout<<"对年龄进行冒泡排序后的英雄数据如下:"<<endl;
for(int a = 0;a<len;a++)
{
cout<< "\t【 "<<heroArray[a].name<<" , "<<heroArray[a].age<<" , "<<heroArray[a].sex<<" 】"<<endl;
}
注意
实践①:
- 计算数组长度时,sizeof(tArray)/sizeof(tArray[0])中前者没有下标
- 函数体参数列表中的数组没有下标但有中括号,如Teacher tArray[]
- 引用函数时实参不需要下标也不需要中括号,如allocate(tArray , len)
- 函数体参数列表中变量前要加上数据类型,如int len
- random最好放到它所用到的函数里,但随机数种子要写在main函数里
- 在字符串变量后加下标可以提取字符串中对应位置的字符(类似数组),如nameseed[0]
- nameseed若在main函数作全局变量则要放于实参导入需要引用到的函数体中,如allocate(tArray , len , nameseed)
- 转义字符:水平制表\t,注意是反斜杠!
实践②:
- 冒泡排序回忆: https://blog.shakuameji.com/archives/cstudy1#冒泡排序
- 无法一次性打印结构体数组内全部内容,即不能直接写heroArray[a]。
每次只能打印结构体数组内的一个数据类型,如heroArray[a].name
下一部分:
C++学习记录 核心篇